NVIDIA
捆绑包 (Bundles) 包含支持特定第三方与 Langflow 集成的自定义组件。
本页面介绍了 NVIDIA 捆绑包中可用的组件。
NVIDIA
该组件使用 NVIDIA LLM 生成文本。 有关 NVIDIA LLM 的更多信息,请参阅 NVIDIA AI 文档。
NVIDIA 参数
| 名称 | 类型 | 描述 |
|---|---|---|
| max_tokens | Integer | 输入参数。要生成的最大 token 数。设置为 0 表示无限制。 |
| model_name | String | 输入参数。要使用的 NVIDIA 模型名称。默认值:mistralai/mixtral-8x7b-instruct-v0.1。 |
| base_url | String | 输入参数。NVIDIA API 的基准 URL。默认值:https://integrate.api.nvidia.com/v1。 |
| nvidia_api_key | SecretString | 输入参数。用于身份验证的 NVIDIA API 密钥。 |
| temperature | Float | 输入参数。控制输出的随机性。默认值:0.1。 |
| seed | Integer | 输入参数。控制作业可复现性的种子。默认值:1。 |
| model | LanguageModel | 输出参数。根据指定参数配置的 ChatNVIDIA 实例。 |
WSL2 上的 NVIDIA NIM
NVIDIA NIM (NVIDIA Inference Microservices) 提供容器来通过 GPU 加速自托管推理微服务。
您可以使用 NVIDIA 组件将 Langflow 与安装了 Windows Subsystem for Linux 2 (WSL2) 的 RTX Windows 系统上的 NVIDIA NIM 连接。
以下示例将 Langflow 中的 NVIDIA 语言模型组件连接到部署在 RTX Windows 系统(带 WSL2)上的 mistral-nemo-12b-instruct NIM。
-
准备您的系统:
-
根据模型说明部署 NIM 容器
不同模型的先决条件各不相同。 例如,要部署
mistral-nemo-12b-instructNIM,请按照您的 模型部署概览 中关于 Windows on RTX AI PCs (Beta) 的说明进行操作。 -
Windows 11 build 23H2 或更高版本
-
至少 12 GB RAM
-
基于 基础提示 (Basic Prompting) 模板创�建一个流。
-
将 OpenAI 模型组件替换为 NVIDIA 组件。
-
在 NVIDIA 组件的 Base URL 字段中,添加您的 NIM 可访问的 URL。如果您遵循了模型的 部署说明,该值为
http://localhost:8000/v1。 -
在 NVIDIA 组件的 NVIDIA API Key 字段中,添加您的 NVIDIA API 密钥。
-
从 Model Name 字段中选择您的模型。
-
打开 游乐场 (Playground) 并与您的 NIM 模型聊天。
NVIDIA 嵌入 (NVIDIA Embeddings)
NVIDIA Embeddings 组件使用 NVIDIA 模型 生成嵌入。
有关在流中使用嵌入模型组件的更多信息,请参阅 嵌入模型组件。
NVIDIA 嵌入参数
| 名称 | 类型 | 描述 |
|---|---|---|
| model | String | 输入参数。用于嵌入的 NVIDIA 模型,例如 nvidia/nv-embed-v1。 |
| base_url | String | 输入参数。NVIDIA API 的基准 URL。默认值:https://integrate.api.nvidia.com/v1。 |
| nvidia_api_key | SecretString | 输入参数。用于通过 NVIDIA 服务进行身份验证的 API 密钥。 |
| temperature | Float | 输入参数。生成嵌入时的模型温度。默认值:0.1。 |
| embeddings | Embeddings | 输出参数。用于生成嵌入的 NVIDIAEmbeddings 实例。 |
请注意您的嵌入模型的块大小 (chunk size) 限制。 如果您的文本块太大,可能会发生分词 (Tokenization) 错误。 有关更多信息,请参阅 由于块大小导致的分词错误.
NVIDIA Rerank
此组件使用 NVIDIA API 查找并对文档进行重新排序 (rerank)。
NVIDIA Retriever Extraction
NVIDIA Retriever Extraction 组件与 NVIDIA nv-ingest 微服务集成,用于数据摄取、处理以及从文本文件中提取内容。
nv-ingest 服务支持 PDF、DOCX 和 PPTX 文件类型的多种提取方法,并包括拆分、分块和嵌入生成等预处理和后处理服务。提取服务的“高分辨率 (High Resolution)”模式使用 nemoretriever-parse 提取方法,以便从扫描的 PDF 文档中获得更高质量的提取结果。此功能仅适用于 PDF 文件。
NVIDIA Retriever Extraction 组件导入 NVIDIA Ingestor 客户端,通过向 NVIDIA 摄取端点发送请求来摄取文件,并将处理后的内容输出为 Data 对象列表。Ingestor 接受其他配置选项,用于从其他文本格式中提取数据。要配置这些选项,请参阅 参数。
NVIDIA Retriever Extraction 也被称为 NV-Ingest 和 NeMo Retriever Extraction。
在流中使用 NVIDIA Retriever Extraction 组件
NVIDIA Retriever Extraction 组件接受 Message 输入,然后输出 Data。该组件调用 NVIDIA Ingest 微服务的端点来摄取本地文件并提取文本。
要在您的流中使用 NVIDIA Retriever Extraction 组件,请按照以下步骤操作:
-
准备您的系统:
-
一个 NVIDIA Ingest 端点。有关设置 NVIDIA Ingest 端点的更多信息,请参阅 NVIDIA Ingest 快速入门。
-
NVIDIA Retriever Extraction 组件需要向您的 Langflow 环境安装额外的依赖项。要在虚拟环境中安装依赖项,请运行以下命令。
- 如果您已克隆 Langflow 仓库并从源码安装:
_10source **YOUR_LANGFLOW_VENV**/bin/activate_10uv sync --extra nv-ingest_10uv run langflow run- 如果您是从 Python Package Index (PyPI) 安装 Langflow:
_10source **YOUR_LANGFLOW_VENV**/bin/activate_10uv pip install --prerelease=allow 'langflow[nv-ingest]'_10uv run langflow run
-
-
将 NVIDIA Retriever Extraction 组件添加到您的流中。
-
在 Base URL 字段中,输入 NVIDIA Ingest 端点的 URL。 您还可以将 URL 存储为 全局变量,以便在多个组件和流中重用。
-
点击 Select Files 选择要摄取的文件。
-
选择要从文件中提取的文本类型:文本 (text)、图表 (charts)、表格 (tables)、图像 (images) 或信息图表 (infographics)。
-
可选:对于 PDF 文件,启用 高分辨率模式 (High Resolution Mode),以便从扫描文档中获得更高质量的提取结果。
-
选择是否将文本拆分为块。
Some parameters are hidden by default in the visual editor. You can modify all parameters through the Controls in the component's header menu.
-
点击 Run component 摄取文件,然后点击 Logs 或 Inspect output 以确认组件已摄取文件。
-
要将处理后的数据存储在向量数据库中,请在流中添加一个向量存储组件,然后将 NVIDIA Retriever Extraction 组件的
Data输出连接到向量存储组件的输入。当您使用向量存储组件运行流时,处理后的数据将存储在向量数据库中。 您可以查询数据库来检索上传的数据。
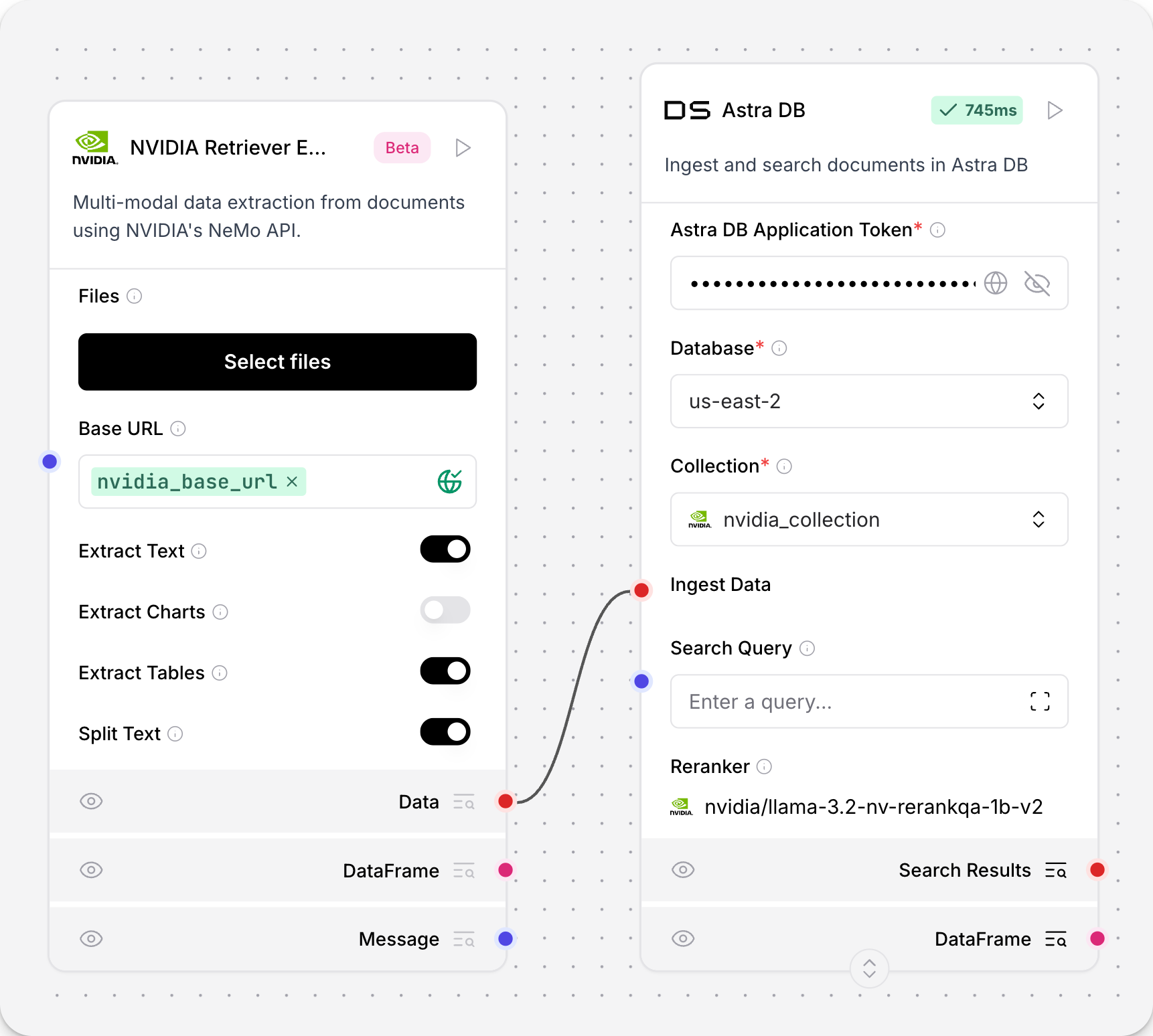
NVIDIA Retriever Extraction 参数
NVIDIA Retriever Extraction 组件具有�以下参数。
有关更多信息,请参阅 NV-Ingest 文档。
输入 (Inputs)
| 名称 | 显示名称 | 信息 |
|---|---|---|
| base_url | NVIDIA Ingestion URL | NVIDIA Ingestion API 的 URL。 |
| path | Path | 要处理的文件路径。 |
| extract_text | Extract Text | 从文档中提取文本。默认值:true。 |
| extract_charts | Extract Charts | 从图表中提取文本。默认值:false。 |
| extract_tables | Extract Tables | 从表格中提取文本。默认值:true。 |
| extract_images | Extract Images | 从文档中提取图像。默认值:true。 |
| extract_infographics | Extract Infographics | 从文档中提取信息图表。默认值:false。 |
| text_depth | Text Depth | 提取文本的层级。选项:'document', 'page', 'block', 'line', 'span'。默认值:page。 |
| split_text | Split Text | 将文本拆分为较小的块。默认值:true。 |
| chunk_size | Chunk Size | 每个块的 token 数量。默认值:500。请确保块大小与您的嵌入模型兼容。有关更多信息,请参阅 由于块大小导致的分词错误。 |
| chunk_overlap | Chunk Overlap | 与上一个块重叠的 token 数量。默认值:150。 |
| filter_images | Filter Images | 过滤图像(请参阅高级选项了解过滤标准)。默认值:false。 |
| min_image_size | Minimum Image Size Filter | 图像的最小宽度/长度(像素)。默认值:128。 |
| min_aspect_ratio | Minimum Aspect Ratio Filter | 允许的最小宽高比(宽/高)。默认值:0.2。 |
| max_aspect_ratio | Maximum Aspect Ratio Filter | 允许的最大宽高比(宽/高)。默认值:5.0。 |
| dedup_images | Deduplicate Images | 过滤重复图像。默认值:true。 |
| caption_images | Caption Images | 使用 NVIDIA 字幕生成模型为图像生成字幕。默认值:true。 |
| high_resolution | High Resolution (PDF only) | 以高分辨率模式处理 PDF,以便从扫描的 PDF 中获得更高质量的提取。默认值:false。 |
输出 (Outputs)
NVIDIA Retriever Extraction 组件输出一个 Data 对象列表,每个对象包含:
text: 提取的内容。- 对于文本文件:提取的文本内容。
- 对于表格和图表:提取的表格/图表内容。
- 对于图像:图像字幕。
- 对于信息图表:提取的信息图表内容。
file_path: 源文件名和路径。document_type: 文档类型,可以是text、structured或image。description: 内容的其他说明。
输出根据 document_type 而有所不同:
-
document_type: "text"的文档包含:- 从文档中提取的原始文本内容,例如 PDF 或 DOCX 文件中的段落。
- 直接存储在
text字段中的内容。 - 使用
extract_text参数提取的内容。
-
document_type: "structured"的文档包含:- 从表格、图表和信息图表中提取的文本,并经过处理以保留结构信息。
- 使用
extract_tables、extract_charts和extract_infographics参数提取的内容。 - 从
table_content元数据处理后存储在text字段中的内容。
-
document_type: "image"的文档包含:- 从文档中提取的图像内容。
- 当启用
caption_images时,存储在text字段中的字幕文本。 - 使用
extract_images参数提取的内容。
NVIDIA System-Assist
NVIDIA System-Assist 组件将您的流与 NVIDIA G-Assist 集成,从而能够通过自然语言提示词与 NVIDIA GPU 驱动程序进行交互。
例如,给 G-Assist 发送提示词 "我的当前 GPU 温度是多少?" 或 "显示可用的 GPU 显存" 来获取信息,然后告诉 G-Assist 修改您的 GPU 设置。
有关更多信息,请参阅 NVIDIA G-Assist 仓库。
-
准备您的系统:
- NVIDIA System-Assist 组件需要 Windows 操作系统上的 NVIDIA GPU。
- It uses the
gassist.risepackage, which is installed with all Langflow versions that include this component.
-
创建一个带有 聊天输入 (Chat Input) 组件、NVIDIA System-Assist 组件和 聊天输出 (Chat Output) 组件的流。
这是一个仅使用三个组件的简化示例。 根据您的使用案例,您的流可能会使用更多组件或不同的输入和输出。
-
将 聊天输入 (Chat Input) 组件连接到 NVIDIA System-Assist 组件的 Prompt 输入。
Prompt 参数接受由 NVIDIA G-Assist AI 助手处理的自然语言提示词。 在此示例中,您将提示词作为聊天输入提供。 您也可以直接在 Prompt 输入中输入提示词,或连接另一个输入组件。
-
将 NVIDIA System-Assist 组件的输出连接到 聊天输出 (Chat Output) 组件。
-
要测试该流,请打开 游乐场 (Playground),然后询问一个关于您的 GPU 的问题。 例如,
"我的当前 GPU 温度是多少?"。通过 NVIDIA System-Assist 组件,NVIDIA G-Assist 会根据提示词查询您的 GPU,然后将响应打印到 游乐场 (Playground)。
该组件的输出是一个包含 NVIDIA G-Assist 响应的
Message。 带有已完成操作结果的字符串响应可以在Message对象的text键中找到。