Docling
捆绑包 (Bundles) 包含支持特定第三方与 Langflow 集成的自定义组件。
Langflow 通过一组用于解析和分块文档的组件与 Docling 集成。
前提条件
-
启用 Windows 开发者模式:
If you are running Langflow Desktop on Windows, you must enable Developer Mode to use the Docling components. The location of this setting depends on your Windows OS version. Find For developers in your Windows Settings, or search for "Developer" in the Windows search bar, and then enable Developer mode. You might need to restart your computer or Langflow to apply the change.
-
安装 Docling 依赖: 要在 Langflow 中使用 Docling 组件,需要安装 Docling 依赖。
-
Langflow 1.6 及更高版本: 除 macOS Intel (x86_64) 外,所有操作系统的默认配置中均包含 Docling 依赖。
对于 macOS Intel (x86_64),请使用 Docling 安装指南 安装 Docling 依赖。
-
早期版本: 1.6 之前的 Langflow 版本不包含 Docling 依赖。 对于 Langflow OSS,请使用
uv pip install 'langflow[docling]'安装 Docling 额外组件。 对于 Langflow Desktop,请将 Docling 依赖添加到 Langflow Desktop 的requirements.txt中。 有关更多信息,请参阅 安装自定义依赖。
-
- Docker/Linux system dependencies: If running Langflow in a Docker container on Linux, you might need to install additional system packages for document processing. For more information, see Document processing errors in Docker containers.
在流中使用 Docling 组件
要了解有关使用 Docling 进行内容提取的更多信息,请观看视频教程 Docling + Langflow: Document Processing for AI Workflows。
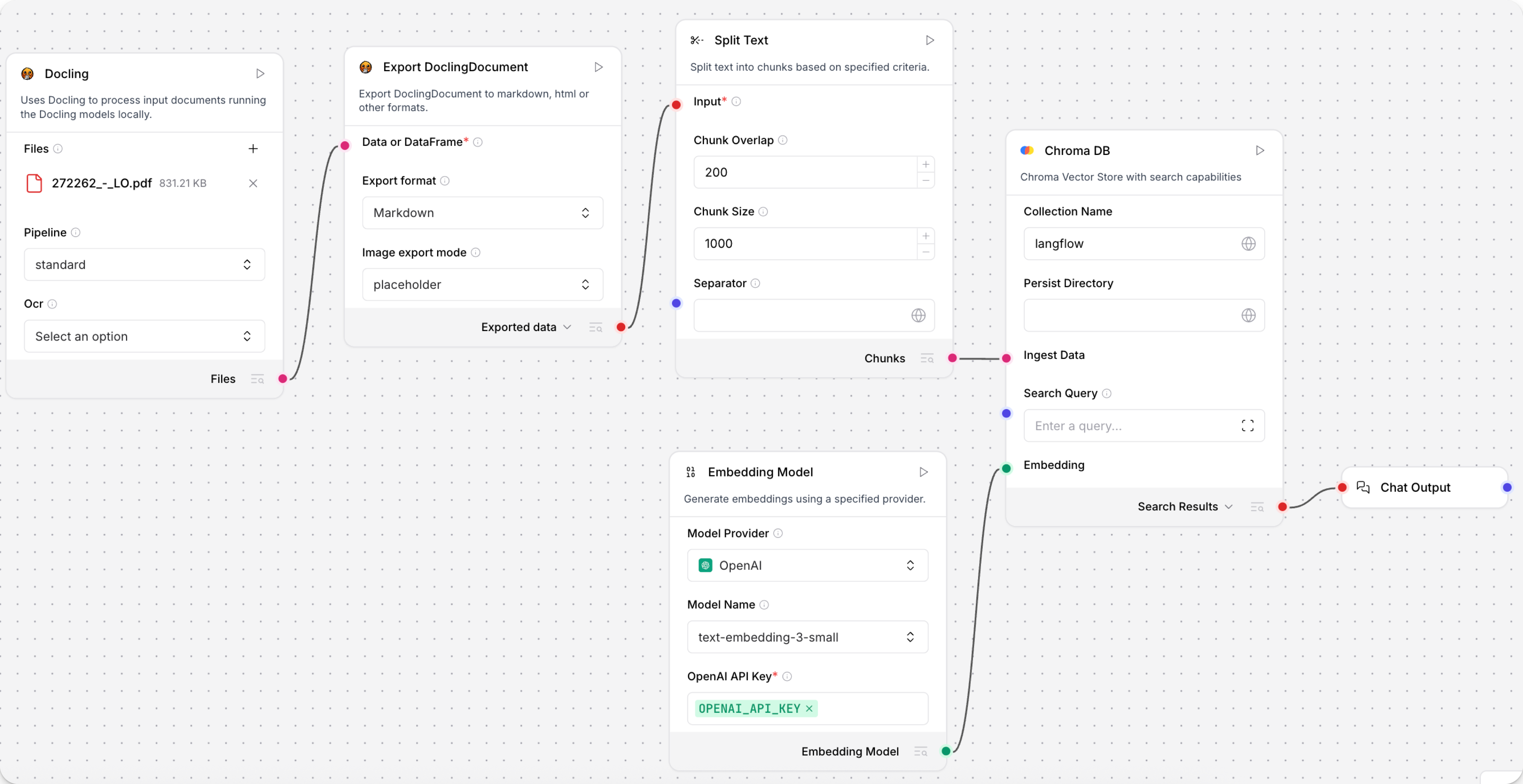
此示例演示了如何在流中使用 Docling 组件拆分 PDF:
-
将 Docling 和 Export DoclingDocument 组件连接到 Split Text 组件。
Docling 组件加载文档,Export DoclingDocument 组件将
DoclingDocument转换为您选择的格式。此示例将文档转换为 Markdown,图像表示为占位符。 Split Text 组件将 Markdown 拆分为块,以便向量数据库在流的下一部分进行存储。 -
将 Chroma DB 向量存储组件 连接到 Split Text 组件的 Chunks 输出。
-
将 嵌入模型组件 连接到 Chroma DB 组件的 Embedding 端口,并连接一个 Chat Output 组件以查看提取的
DataFrame。 -
在嵌入模型组件中,选择您首选的模型,提供凭据,并根据需要配置其他设置。
-
向 Docling 组件添加文件。
-
要运行流,请单击 Playground。
分块后的文档将作为向量加载到您的向量数据库中。
Docling 组件
以下部分介绍了 Docling 捆绑包中每个组件的用途和配置选项。
Docling 本地模型 (Docling local model)
Docling ��组件摄取文档,然后通过运行本地 Docling 模型使用 Docling 对其进行处理。
它输出 files,即带有 DoclingDocument 数据的已处理文件。
有关更多信息,请参阅 Docling IBM 模型项目仓库。
Docling 参数
| 名称 | 类型 | 描述 |
|---|---|---|
| files | File | 要处理的文件。 |
| pipeline | String | 要使用的 Docling 流水线 (standard, vlm)。 |
| ocr_engine | String | 要使用的 OCR 引擎 (easyocr, tesserocr, rapidocr, ocrmac)。 |
Docling Serve
Docling Serve 组件摄取文档并使用 Docling API 服务(而非本地模型)对其进行处理。
它输出 files,即带有 DoclingDocument 数据的已处理文件。
有关更多信息,请参阅 Docling serve 项目仓库。
Docling Serve 参数
| 名称 | 类型 | 描述 |
|---|---|---|
| files | File | 要处理的文件。 |
| api_url | String | Docling Serve 实例的 URL。 |
| max_concurrency | Integer | 服务器的最大并发请求数。 |
| max_poll_timeout | Float | 等待文档转换完成的最大时间。 |
| api_headers | Dict | 连接到 Docling Serve 所需的其他可选标头字典。 |
| docling_serve_opts | Dict | Docling Serve 的其他可选选项字典。 |
拆分 DoclingDocument (Chunk DoclingDocument)
Chunk DoclingDocument 组件将 DoclingDocument 对象拆分为块。
它以 DataFrame 形式输出分块后的文档。
有关更多信息,请参阅 Docling core 项目仓库。
Chunk DoclingDocument 参数
| 名称 | 类型 | 描述 |
|---|---|---|
| data_inputs | Data/DataFrame | 包含要拆分为块的文档的数据。 |
| chunker | String | 使用哪个分块器 (HybridChunker, HierarchicalChunker)。 |
| provider | String | 哪个分词器提供商 (Hugging Face, OpenAI)。 |
| hf_model_name | String | 选择 Hugging Face 时,HybridChunker 要使用的分词器模�型名称。 |
| openai_model_name | String | 选择 OpenAI 时,HybridChunker 要使用的分词器模型名称。 |
| max_tokens | Integer | HybridChunker 的最大 token 数量。 |
| doc_key | String | 用于 DoclingDocument 列的键名。 |
导出 DoclingDocument (Export DoclingDocument)
Export DoclingDocument 组件将 DoclingDocument 导出为 Markdown、HTML 和其他格式。
它可以将导出的数据输出为 Data 或 DataFrame。
有关更多信息,请参阅 Docling core 项目仓库。
Export DoclingDocument 参数
| 名称 | 类型 | 描述 |
|---|---|---|
| data_inputs | Data/DataFrame | 包含要导出的文档的数据。 |
| export_format | String | 选择转换输入的导出格式 (Markdown, HTML, Plaintext, DocTags)。 |
| image_mode | String | 指定图像在输出中的导出方式 (placeholder, embedded)。 |
| md_image_placeholder | String | 指定 Markdown 导出的图像占位符。 |
| md_page_break_placeholder | String | 在 Markdown 输出的页面之间添加此占位符。 |
| doc_key | String | 用于 DoclingDocument 列的键名。 |