语言模型 (Language Model)
Langflow 中的语言模型组件使用指定的大语言模型 (LLM) 生成文本。 这些组件接受聊天消息、文件和指令等输入,以生成文本响应。
Langflow 包含一个 语言模型 (Language Model) 核心组件,内置支持多种 LLM。 或者,您可以使用任何 其他语言模型 来代替 语言模型 核心组件。
在流中使用语言模型组件
在流中任何需要使用 LLM 的地方都可以使用语言模型组件。
- 聊天 (Chat)
- 驱动器 (Drivers)
- 代理 (Agents)
语言模型组件最常见的用例之一是在流中与 LLM 聊天。
以下示例在类似于 基础提示 (Basic Prompting) 模板的聊天机器人流中使用语言模型组件。
-
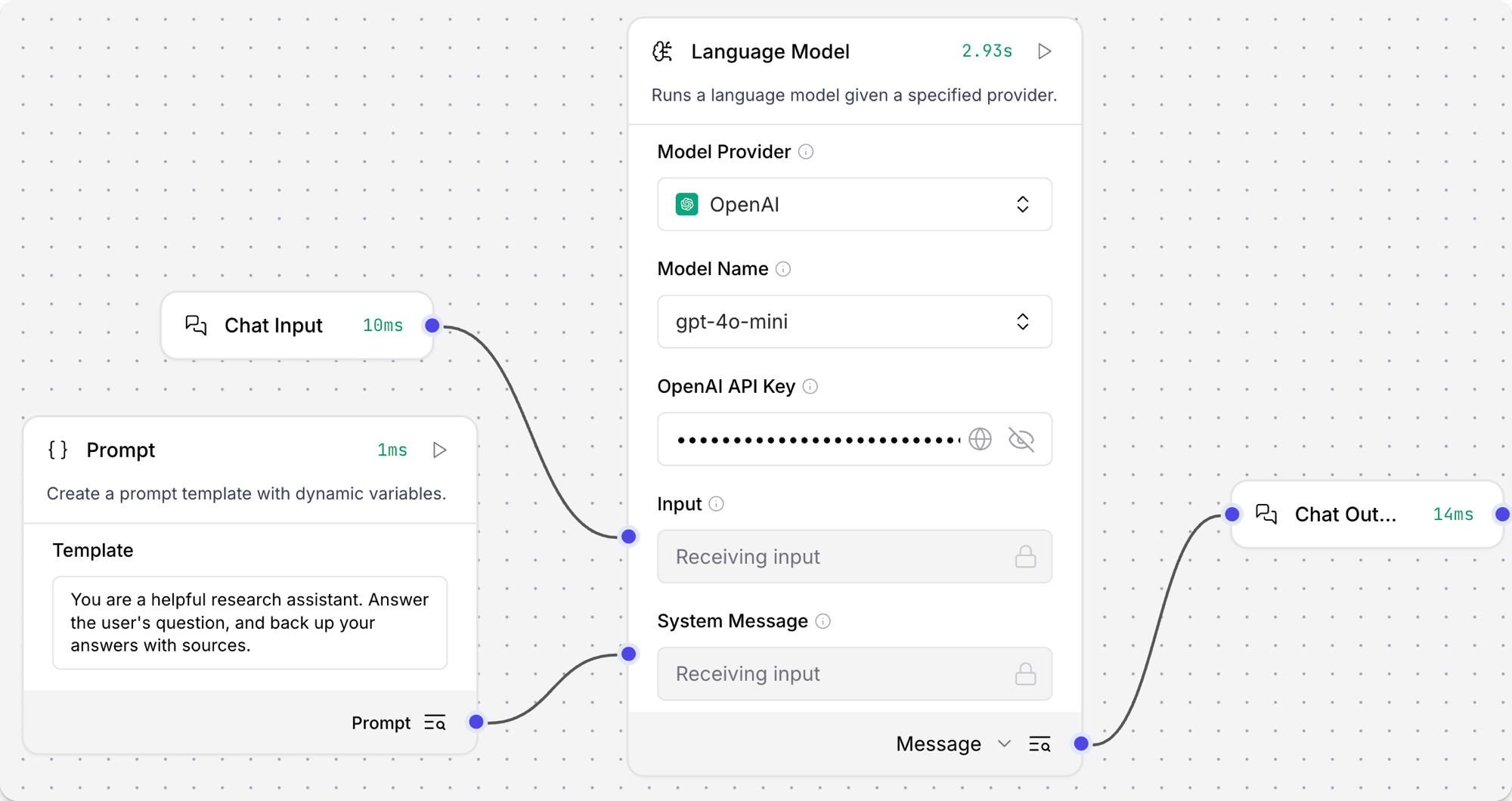
将 语言模型 (Language Model) 核心组件添加到您的流中,然后输入您的 OpenAI API 密钥。
此示例使用 语言模型 核心组件默认的 OpenAI 模型。 如果您想使用不同的提供商或模型,请相应地编辑 模型提供商 (Model Provider)、模型名称 (Model Name) 和 API 密钥 (API Key) 字段。
我喜欢的提供商或模型未列出如果您想使用 语言模型 核心组件未内置的提供商或模型,可以使用任何 其他语言模型 替换此组件。
浏览 捆绑包 (Bundles) 或 搜索 您喜欢的提供商以查找其他语言模型。
-
在 组件的页眉菜单 中,点击 控制 (Controls),启用 系统消息 (System Message) 参数,然后点击 关闭。
-
向您的流中添加一个 提示词模板 (Prompt Template) 组件。
-
在 模板 (Template) 字段中,输入给 LLM 的一些指令,例如
You are an expert in geography who is tutoring high school students(你是一位正在辅导高中生的地理专家)。 -
将 提示词模板 组件的输出连接到 语言模型 组件的 系统消息 (System Message) 输入。
-
向您的流中添加 聊天输入 (Chat Input) 和 聊天输出 (Chat Output) 组件。 这些组件是与 LLM 进行直接聊天交互所必需的。
-
将 聊天输入 组件连接到 语言模型 组件的 输入 (Input),然后将 语言模型 组件的 消息 (Message) 输出连接到 聊天输出 组件。
-
打开 游乐场 (Playground),向 LLM 提问以聊天并测试流,例如
What is the capital of Utah?(犹他州的首府是哪里?)。结果
以下响应是 OpenAI 模型响应的一个示例。 您的实际响应可能会根据请求时的模型版本、您的模板和输入而有所不同。
_10犹他州的首府是盐湖城 (Salt Lake City)。它不仅是该州最大的城市,还是犹他州的文化和经济中心。盐湖城由摩门教先驱于 1847 年建立,因其靠近大盐湖以及在耶稣基督后期圣徒教会历史中的作用而闻名。欲了解更多信息,您可以参考美国地质调查局或犹他州官方网站等来源。 -
可选:尝试不同的模型或提供商,看看响应如何变化。 例如,如果您使用的是 语言模型 核心组件,您可以尝试 Anthropic 模型。
然后,打开 游乐场,问与之前相同的问题,并比较响应的内容和格式。
这有助于您了解不同模型如何处理相同的请求,以便为您的用例选择最佳模型。 您还可以在每个模型提供商的文档中了解有关不同模型的更多信息。
结果
以下响应是 Anthropic 模型响应的一个示例。 您的实际响应可能会根据请求时的模型版本、您的模板和输入而有所不同。
请注意,此响应较短并包含来源,而之前的 OpenAI 响应更像百科全书且未引用来源。
_10犹他州的首府是盐湖城。它也是该州人口最多的城市。自 1896 年犹他州建州以来,盐湖城一直是其首府。_10来源:_10犹他州政府官方网站 (utah.gov)_10美国普查局_10大英百科全书
某些组件使用语言模型组件来执行 LLM 驱动的操作。 通常,这些组件为下游组件的进一步处理准备数据,而不是发出直接的聊天输出。 示例请参阅 智能转换 (Smart Transform) 组件。
组件必须接受 LanguageModel 输入才能使用语言模型组件作为驱动器,并且您必须将语言模型组件的输出类型设置为 LanguageModel。
有关更多信息,请参阅 语言模型输出类型。
如果您不想使用 代理 (Agent) 组件内置的 LLM,可以使用语言模型组件连接您喜欢的模型:
-
向流中添加一个语言模型组件。
您可以使用 语言模型 核心组件或浏览 捆绑包 (Bundles) 以查找其他语言模型。 捆绑包中的组件名称中可能不包含
language model。 例如,Azure OpenAI LLM 是通过 Azure OpenAI 组件 提供的。 -
根据需要配置语言模型组件以连接到您喜欢的模型。
-
将语言模型组件的输出类型从 模型响应 (Model Response) 更改为 语言模型 (Language Model)。 输出端口会变为
LanguageModel端口。 这是将语言模型组件连接到 代理 组件所必需的。 有关更多信息,请参阅 语言模型输出类型。 -
向流中添加一个 代理 (Agent) 组件,然后将 模型提供商 (Model Provider) 设置为 连接其他模型 (Connect other models)。
模型提供商 字段会变为 语言模型 (
LanguageModel) 输入。 -
将语言模型组件的输出连接到 代理 组件的 语言模型 (Language Model) 输入。 代理 组件现在将从连接的语言模型组件继承语言模型设置,而不是使用任何内置模型。
语言模型参数
以下参数适用于 语言模型 (Language Model) 核心组件。 其他语言模型组件可能具有其他或不同的参数。
Some parameters are hidden by default in the visual editor. You can modify all parameters through the Controls in the component's header menu.
| 名称 | 类型 | 描述 |
|---|---|---|
| provider | 字符串 | 输入参数。要使用的模型提供商。 |
| model_name | 字符串 | 输入参数。要使用的模型名称。选项取决于所选的提供商。 |
| api_key | SecretString | 输入参数。用于所选提供商身份验证的 API 密钥。 |
| input_value | 字符串 | 输入参数。发送给模型的输入文本。 |
| system_message | 字符串 | 输入参数。帮助设置助手行为的系统消息。 |
| stream | 布尔值 | 输入参数。是否流式传输响应。默认值:false。 |
| temperature | 浮点数 | 输入参数。控制响应的随机性。范围:[0.0, 1.0]。默认值:0.1。 |
| model | LanguageModel | 输出参数。默认 Message 输出的替代输出类型。产生一个配置了指定参数的 Chat 实例。参见 语言模型输出类型。 |
语言模型输出类型
语言模型组件(包括核心组件和捆绑组件)可以产生两种类型的输出:
-
模型响应 (Model Response):默认输出类型,以
Message数据 的形式发出模型生成的响应。 当您想要典型的 LLM 交互(即 LLM 根据给定输入生成文本响应)时,请使用此输出类型。 -
语言模型 (Language Model):当您需要将 LLM 附加到流中的另一个组件(如 代理 (Agent) 或 智能转换 (Smart Transform) 组件)时,请将语言模型组件的输出类型更改为
LanguageModel。在这种配置下,语言模型组件支持由另一个组件完成的操作,而不是直接的聊天交互。 例如,智能转换 组件使用 LLM 从自然语言输入创建函数。
其他语言模型
如果您的提供商或模型不受 语言模型 (Language Model) 核心组件支持,可以在 捆绑包 (Bundles) 中找到其他语言模型组件。
您可以像使用核心 语言模型 组件一样使用这些组件,如 在流中使用语言模型组件 中所述。
模型与向量库配对
By design, vector data is essential for LLM applications, such as chatbots and agents.
While you can use an LLM alone for generic chat interactions and common tasks, you can take your application to the next level with context sensitivity (such as RAG) and custom datasets (such as internal business data). This often requires integrating vector databases and vector searches that provide the additional context and define meaningful queries.
Langflow includes vector store components that can read and write vector data, including embedding storage, similarity search, Graph RAG traversals, and dedicated search instances like OpenSearch. Because of their interdependent functionality, it is common to use vector store, language model, and embedding model components in the same flow or in a series of dependent flows.
To find available vector store components, browse Bundles or Search for your preferred vector database provider.
示例:向量搜索流
For a tutorial that uses vector data in a flow, see Create a vector RAG chatbot.
The following example demonstrates how to use vector store components in flows alongside related components like embedding model and language model components. These steps walk through important configuration details, functionality, and best practices for using these components effectively. This is only one example; it isn't a prescriptive guide to all possible use cases or configurations.
-
Create a flow with the Vector Store RAG template.
This template has two subflows. The Load Data subflow loads embeddings and content into a vector database, and the Retriever subflow runs a vector search to retrieve relevant context based on a user's query.
-
Configure the database connection for both Astra DB components, or replace them with another pair of vector store components of your choice. Make sure the components connect to the same vector store, and that the component in the Retriever subflow is able to run a similarity search.
The parameters you set in each vector store component depend on the component's role in your flow. In this example, the Load Data subflow writes to the vector store, whereas the Retriever subflow reads from the vector store. Therefore, search-related parameters are only relevant to the Vector Search component in the Retriever subflow.
For information about specific parameters, see the documentation for your chosen vector store component.
-
To configure the embedding model, do one of the following:
-
Use an OpenAI model: In both OpenAI Embeddings components, enter your OpenAI API key. You can use the default model or select a different OpenAI embedding model.
-
Use another provider: Replace the OpenAI Embeddings components with another pair of embedding model components of your choice, and then configure the parameters and credentials accordingly.
-
Use Astra DB vectorize: If you are using an Astra DB vector store that has a vectorize integration, you can remove both OpenAI Embeddings components. If you do this, the vectorize integration automatically generates embeddings from the Ingest Data (in the Load Data subflow) and Search Query (in the Retriever subflow).
提示If your vector store already contains embeddings, make sure your embedding model components use the same model as your previous embeddings. Mixing embedding models in the same vector store can produce inaccurate search results.
-
-
Recommended: In the Split Text component, optimize the chunking settings for your embedding model. For example, if your embedding model has a token limit of 512, then the Chunk Size parameter must not exceed that limit.
Additionally, because the Retriever subflow passes the chat input directly to the vector store component for vector search, make sure that your chat input string doesn't exceed your embedding model's limits. For this example, you can enter a query that is within the limits; however, in a production environment, you might need to implement additional checks or preprocessing steps to ensure compliance. For example, use additional components to prepare the chat input before running the vector search, or enforce chat input limits in your application code.
-
In the Language Model component, enter your OpenAI API key, or select a different provider and model to use for the chat portion of the flow.
-
Run the Load Data subflow to populate your vector store. In the Read File component, select one or more files, and then click Run component on the vector store component in the Load Data subflow.
The Load Data subflow loads files from your local machine, chunks them, generates embeddings for the chunks, and then stores the chunks and their embeddings in the vector database.
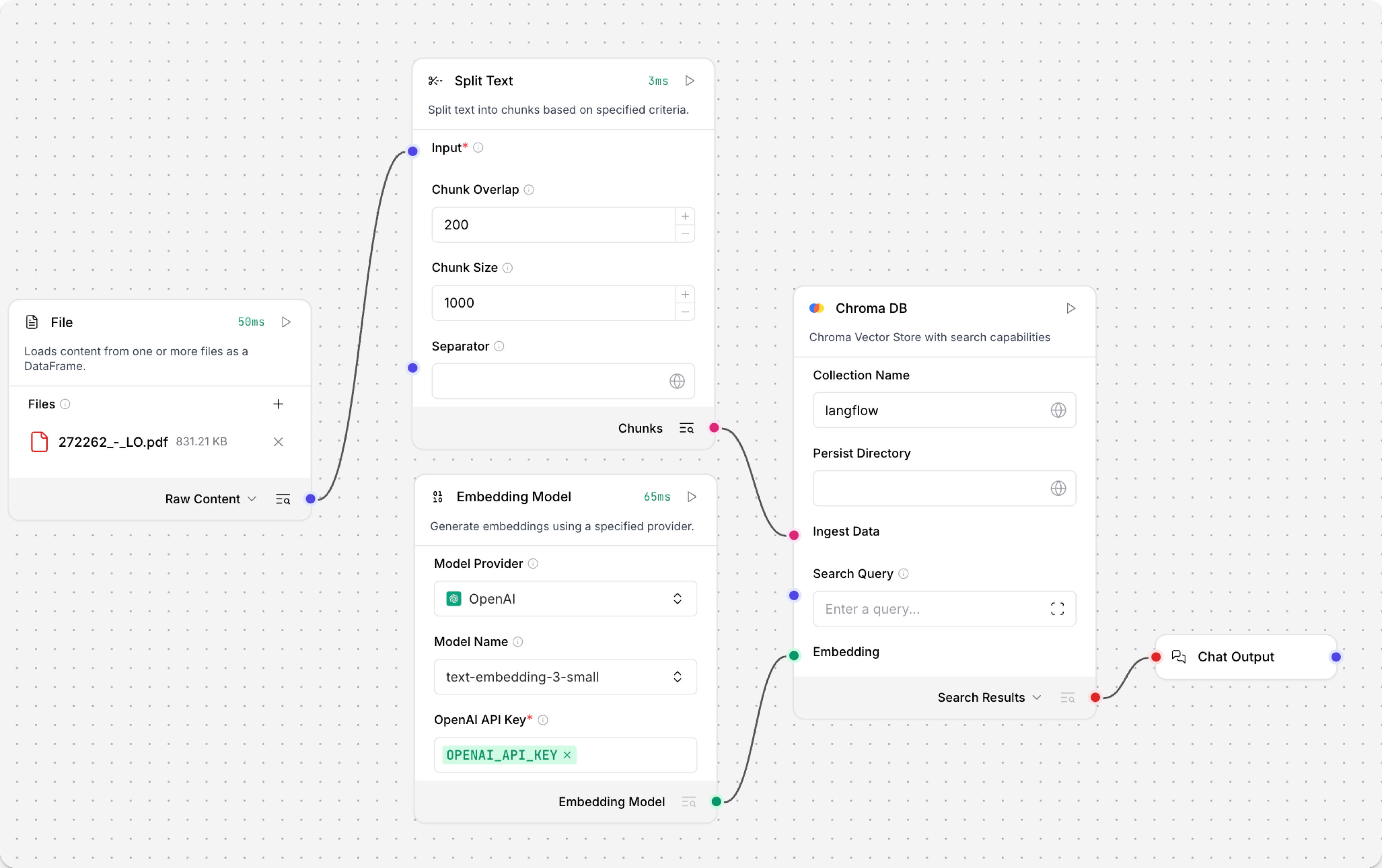
The Load Data subflow is separate from the Retriever subflow because you probably won't run it every time you use the chat. You can run the Load Data subflow as needed to preload or update the data in your vector store. Then, your chat interactions only use the components that are necessary for chat.
If your vector store already contains data that you want to use for vector search, then you don't need to run the Load Data subflow.
-
Open the Playground and start chatting to run the Retriever subflow.
The Retriever subflow generates an embedding from chat input, runs a vector search to retrieve similar content from your vector store, parses the search results into supplemental context for the LLM, and then uses the LLM to generate a natural language response to your query. The LLM uses the vector search results along with its internal training data and tools, such as basic web search and datetime information, to produce the response.
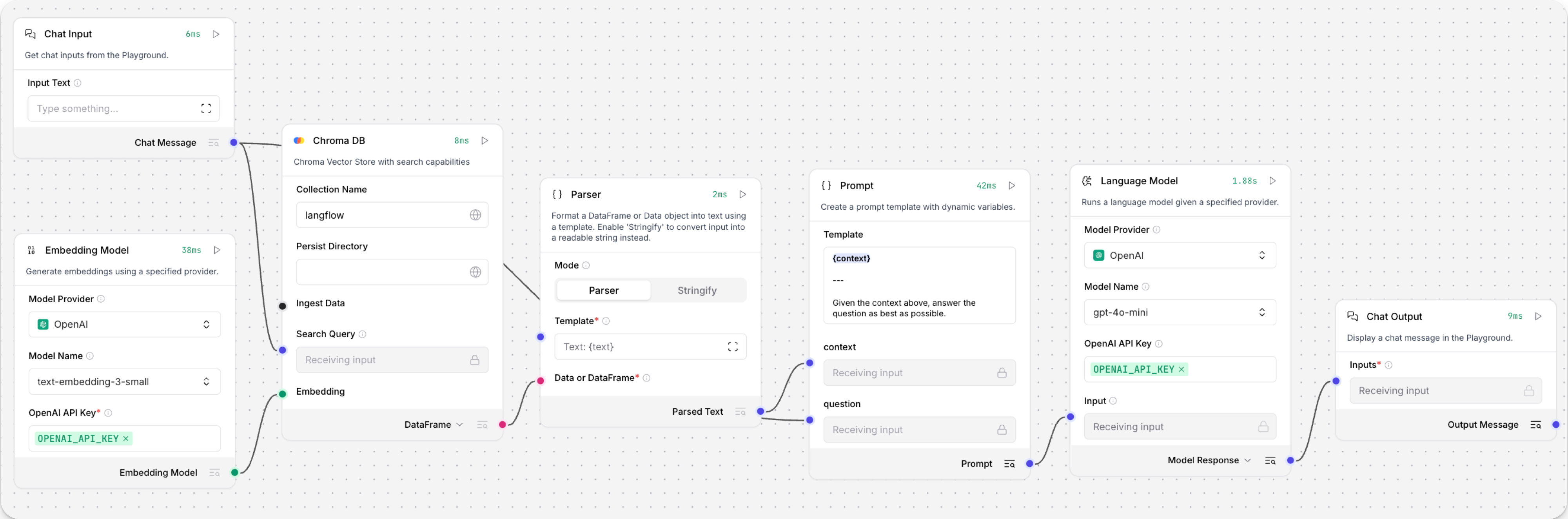
To avoid passing the entire block of raw search results to the LLM, the Parser component extracts
textstrings from the search resultsDataobject, and then passes them to the Prompt Template component inMessageformat. From there, the strings and other template content are compiled into natural language instructions for the LLM.You can use other components for this transformation, such as the Data Operations component, depending on how you want to use the search results.
To view the raw search results, click Inspect output on the vector store component after running the Retriever subflow.